
If you’re reading this, you are likely aware of the current supply chain challenges in the U.S. My guess is you’ve also been impacted by the drag it’s creating on economic activity. There are multiple reasons why the U.S. supply chain is in its current condition, but what’s important is understanding that the U.S. supply chain, or any supply chain for that matter, is essentially a network of systems. And when any part of that system fails or becomes overwhelmed, it impacts the entire supply chain.
When this concept of interconnectedness is scaled down to buildings, similar things can happen with building controls systems and building controls data. Without a solid data supply chain, building controls systems can become a drag on building operations and occupants.
Before we dive into how building controls data supply chains can impact a building, let’s both define a supply chain and data supply chain.
What is a Supply Chain?
At its most basic definition, a supply chain is a series of steps and processes to get a product, service, or resource from its origin to its end user. In the case of the U.S. supply chain, it is more precisely a network of systems, and each of those systems can have their own supply chains that support the larger supply chain.
Imagine wanting to sell bamboo furniture. You’re probably thinking about the style of furniture you’d create and sell. But what if you had to grow your own bamboo, harvest it, refine/process it, and store it, all before you could shape and create your furniture? That might make the process of creating the furniture much more daunting, if not impossible. Within a supply chain, this process would be broken into small pieces that are performed by a network of independent, interconnected entities in an efficient and cost-effective manner.

What is a Data Supply Chain?
A data supply chain is the process of transferring data from its source to its end user. The end user may be a data scientist, a building’s facilities manager, or another process that consumes the data as a part of a larger data supply chain. Think of temperature sensor data being transmitted to an air handling unit controller, and that air handling unit controller data being transferred to the building automation system controller.
A data supply chain is important for many of the same reasons as a common supply chain: it builds efficiency and cost-effectiveness into our data streams. It’s also possible that it’s more important than we presume. As the world becomes more reliant on data, we inherently need to trust it more. Therefore, a reliable, high-quality data supply chain is crucial.
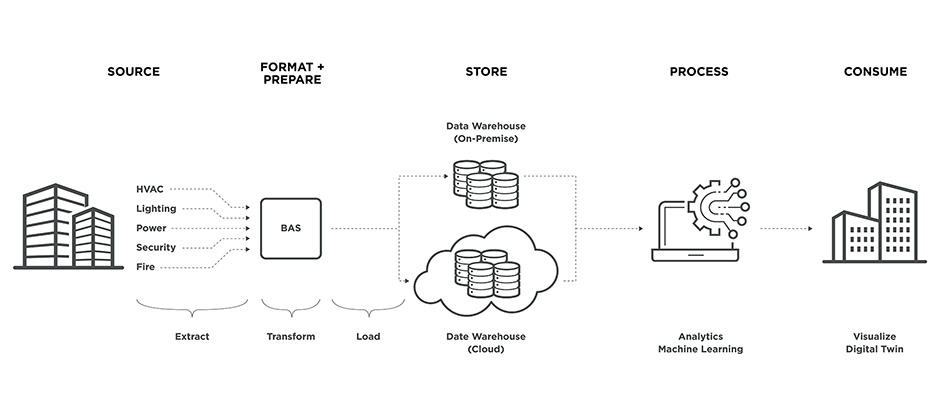
A data supply chain has the following key steps:
This refers to the origin point where each individual piece of data is created. Reliability is key at this stage. An unreliable source of data will impact every other step along the way.
At this critical stage, the data that was created by the source is transformed. The transformation involves applying a set of rules of functions to the extracted data to make it functional for the end user.
This step also includes data cleansing to help ensure that only the appropriate data will go through the process. One of the biggest challenges in this phase occurs when there are a variety of systems trying to interact and send data in varying formats, which may differ from what is needed by the end user.
Another key process in this step is checking for data integrity to maintain data accuracy and consistency over its life cycle.
Furthermore, the importance of formatting and preparing data appropriately cannot be overlooked. No matter the quality of the data extracted, if it isn’t transformed to meet the needs of the end user, it might as well be thrown out.
Once data has been formatted and prepared, it is passed along to a data lake or data warehouse depending on the specific needs. A data lake stores unstructured, semi-structured, and raw data. Data lakes generally do not require transformation of the data prior to storage. However, the stored data requires formatting and preparation (transformation) prior to processing and use.
On the other hand, a data warehouse stores structured, transformed data that is ready to be utilized. Prior to storage in a data warehouse, the data undergoes many of the transformation processes discussed in the formatting and preparation stages.
It’s important to consider data storage methodology as the selected method impacts where the data will need to be transformed within the data supply chain, overall data supply chain costs (data lake vs. data warehouse), and the ultimate end goal.
In this step, a variety of processes can be applied to the stored data. Understanding which processes the data will undergo at the beginning of a project is vital as each process may have specific data structuring requirements to properly implement. For instance, this stage is where raw data stored in a data lake is transformed for use. Machine learning and analytics are both processes that rely heavily on the transformed data.
This phase is what most people think of when referring to data analytics, machine learning, and data visualization. We are the consumers of data and our decisions and inferences are made based on what is presented to us. However, some data supply chains are fed into other, more complex, data supply chains.
What About Building Controls Data?
Simply stated, building controls data is data created by sensors installed throughout the built environment that provide awareness of building conditions at any given moment. For instance, a temperature sensor installed in an office provides temperature data that can be used to inform the occupant about indoor conditions as well as direct the HVAC system on whether there is a call for cooling or heating in the space.
The Importance of the Data Supply Chain in Regard to Building Controls Data
As mentioned earlier, the world is becoming more reliant on data. Building controls systems are no different as they have been transitioning from analog to digital in recent years. Nearly every building controls system is now available with digital controls, which means it creates and consumes data.
With all this data floating around, there is plenty of opportunity to put it to good use. But without an efficient data supply chain, all that data could just go to waste. That’s the importance of an effective data supply chain. It provides an intentional way for building data to go from sensors to a data lake/warehouse, and ultimately to the end user – just like any other supply chain.
The Exciting Possibilities of a Reliable, High-Quality Data Supply Chain
With a proper data supply chain in place to move building controls data from sensors to a data lake/warehouse, it sets the stage for optimizing building system operations. Optimized building controls systems are a foundational component on the roadmap to regenerative buildings, which are designed to have a net-positive environmental impact.
Quality data supply chains also enable reliable digital twins, which are virtual, identical representations of building systems. As Adam Roth, our director of BIM/VDC, recently wrote about, there are different levels of digital twins.
The desired digital twin level informs the complexity and robustness of the building controls data supply chain. For instance, a descriptive digital twin might not derive a ton of benefit from a building controls data supply chain since it is essentially a static model of the constructible design. On the other end of the spectrum, an autonomous digital twin would rely heavily on the building controls data supply chain. Knowing this, much care and intention must go into developing the data supply chain for these types of digital twins.
Feel free to connect with me if you’d like to learn more about how quality data supply chains benefit the built environment.

The latest installment in a series of articles focused on computational thinking’s role in problem-solving, specifically as it pertains to the architecture, engineering, and construction industry.
Read More
ASCs are a great fit for office conversions due to the square footage they require, but there are some challenges to watch out for.
Read MoreJoin our email list to get the latest design innovations, technical content, new projects, and research from Henderson’s experts delivered straight to your inbox.
